大数据计算与智能:CDH/CDP
CDP(Cloudera Data Platform)是Cloudera和Hortonworks合并后,选择原CDH和HDP中的精华组件,合并成新一代数据平台。该平台可以灵活地运⾏各种企业⼯作负载,⽀持从边缘计算到⼈⼯智能的多功能数据分析,提供企业级的安全模型来保证客户数据安全。
产品优势
-

提⾼开源组织版本管理效率,快速⽀持业务创新
- 1、更多开源软件⽀持
- 2、更⾼软件版本⽀持
- 3、覆盖从边缘到AI全场景
-

企业级服务⽀持,降低运维成本,缩短故障处理时间
- 1、7*24⼩时⼤数据专家服务⽀持
- 2、快速定位问题,缩短故障处理时间
- 3、企业级管理组件,降低运维复杂度
-

更专业的数据安全和治理,满⾜数据合规要求
- 1、基于元数据的安全和治理技术
- 2、简化多⽤户数据访问分析,对数据访问进⾏管控
- 3、符合法规要求,减少数据安全⻛险
构建现代化数据仓库来替代传统数据仓库以解决企业对数据来源、数据量及数据服务时效的需求,使得现代化数据仓库可以使用强大的自助服务工具来为数千名BI分析用户提供支持,同时系统提供快速和大规模的向导和自动化管理工具,并且存储所有的数据(包括各种类型和数据量的数据)。
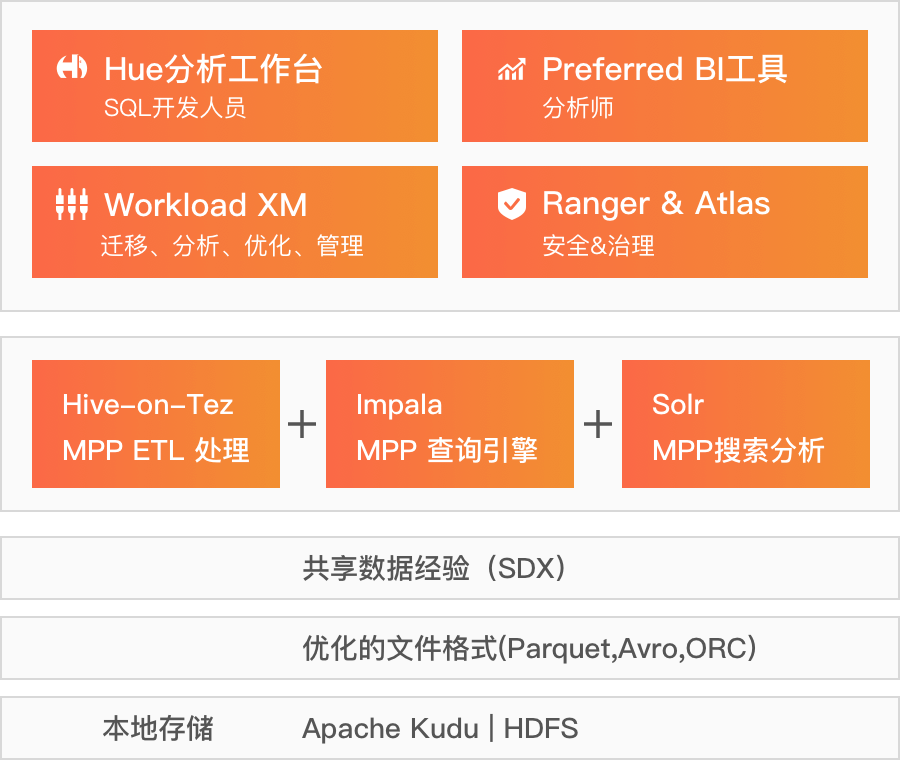
现代数据仓库
构建现代化数据仓库来替代传统数据仓库以解决企业对数据来源、数据量及数据服务时效的需求,使得现代化数据仓库可以使用强大的自助服务工具来为数千名BI分析用户提供支持,同时系统提供快速和大规模的向导和自动化管理工具,并且存储所有的数据(包括各种类型和数据量的数据)。
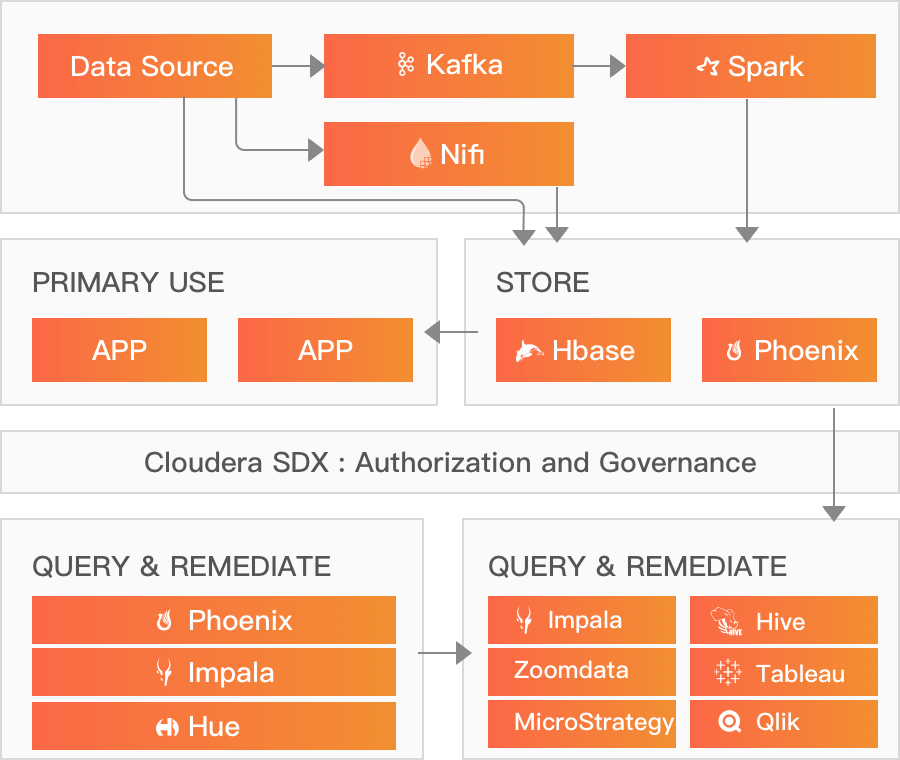
运营数据库
Cloudera运营数据库提供了实时的、始终可用的、可扩展的运营数据库,该数据库在统一的运营和仓储平台中为传统结构化数据和非结构化数据提供服务。运营数据库由Apache HBase和Apache Phoenix提供支持。
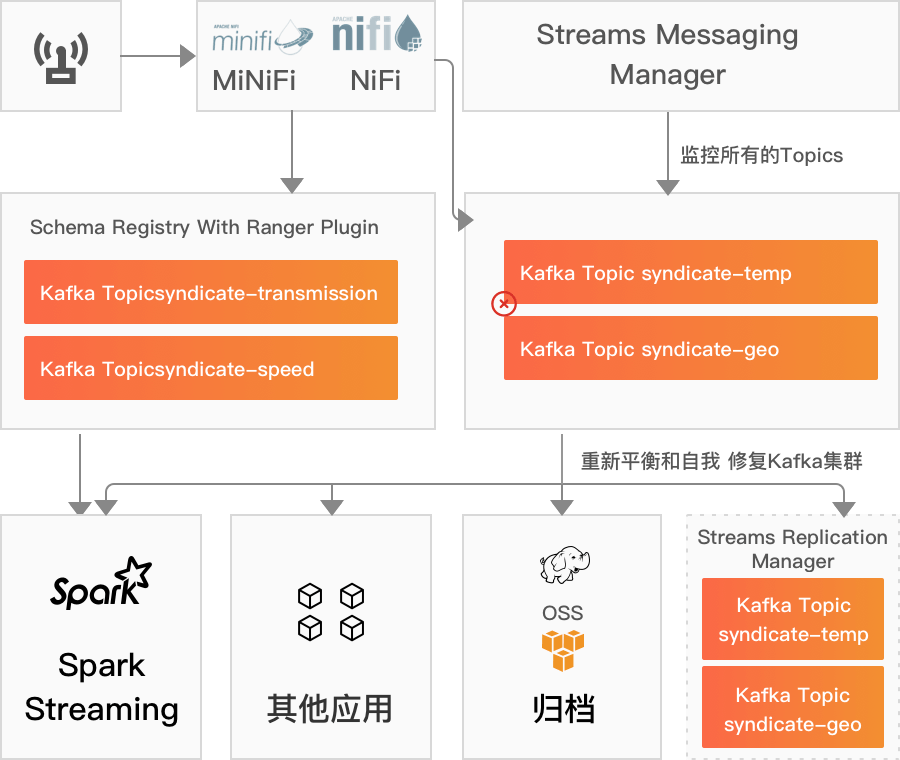
流式消息处理
Apache Kafka是一个高性能、高可用性的冗余流消息平台。在CDP中提供了Kafka及其周边的小伙伴,来使得Kafka更易用,更好用。使用CDP7.1,您将获得最新的Kafka服务。
- 在边缘端显示为Apache MiNiFi,它从移动资产中提取了机器生成的数据。
- Apache NiFi收集数据并转换、解析和过滤到Kafka的主题,以便Apache Flink/Spark Streaming等流处理引擎运行分析。
- Kafka Connect支持可用于增强与HDFS、S3和Kafka Streams的连接,直接将Kafka的数据写入到对应的存储中。
- Schema Registry将在整个Kafka集群中存储和访问您的Schema。它与Apache Ranger集成,来支持对Schema Registry的访问控制。
- Stream Replication Manager可实现业务连续性,该业务连续性支持您的Kafka群集的复制,以实现灾难恢复和高可用性需求。
- Cruise Control支持提供基于API的工具,以监视和协助Kafka集群和主题的重新平衡和扩展。
- Streams Messaging Manager用于监控和管理发布者、代理、使用者和主题。
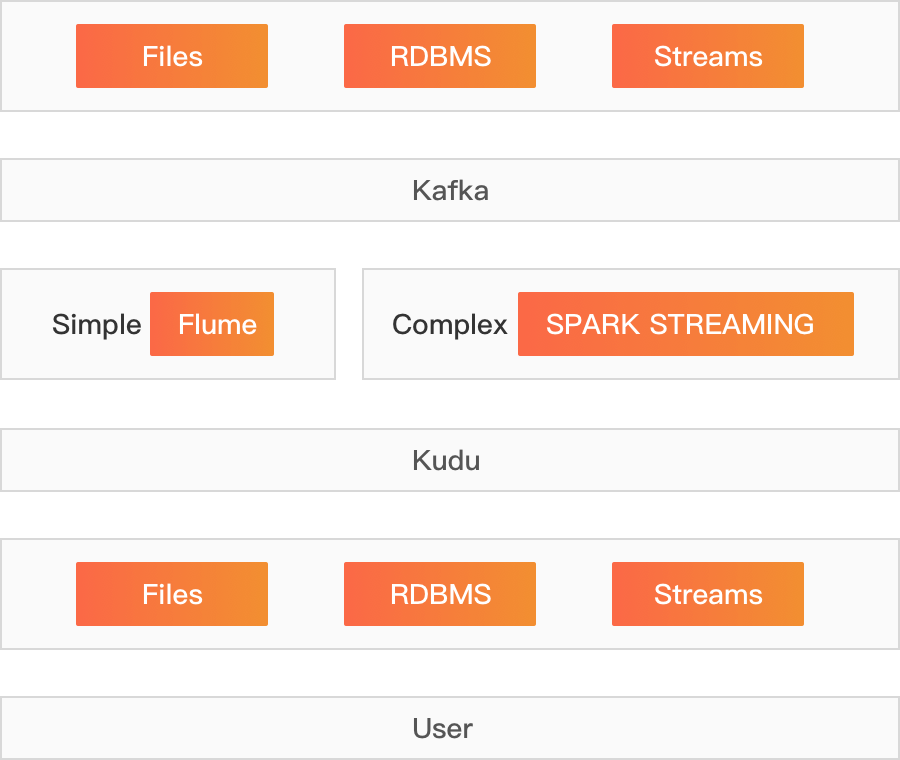
准实时分析
准实时分析需要对变化中的数据提供快速分析能力,包括结合历史数据和实时流数据进行汇总分析、预测和明细查询。 准实时分析的典型场景需要同时支持顺序和随机读/写的应用场景,包括:
-
在线交互式BI分析/决策辅助
- 场景举例: 贷后风险实时监测,实时资产偏好视图,历史风险偏好趋势,市场监测
- 应用类型: 需要准实时的同步插入/修改,同时汇总分析和单条查询
-
时间序列数据
- 场景举例: 股市行情数据; 欺诈检测和预防; 风险监控;线上实时反欺诈
- 应用类型:需要实时捕获流数据,同时结合已有的T+1数据进行汇总、分析和计算 • 机器日志数据分析
- 场景举例: 台机监控、故障预警
- 应用类型:需要过滤大量流数据,同时结合已有的T+1数据进行汇总、分析和计算 在CDP平台上通过使用Kudu+Impala的架构来提供准实时数据分析,这里只使用一套系统,不再需要后台定时的批处理任务来同步数据,可以轻松应对数据延迟和数据修复工作,新数据可以立即用于分析和业务运营。
数据洞察Spark
基于Apache Spark的全托管数据分析平台, 内核采用更高效、稳定的商业版Databricks Runtime和Delta Lake。可同时满足数据分析师、数据开发工程师和数据科学家的分析需求,实现协同合作和数据共享。满足用户在大数据下对数据湖分析、实时数仓、离线数仓、BI数据分析、AI机器学习等场景需求。
全托管分析平台
快速拉起Spark全托管的集群,操作简单,按需付费。集群规模
用户根据需求设置节点数量,支持集群高可用。
机型选择
支持ECS通用型、计算型和内存型三种实例规格族。
弹性能力
集群规模可动态扩展,调整计算资源大小,达到成本最优。
交互式协同工作
多种用户角色共享数据,交互式协同合作。Notebook
可以协同工作的工作空间,交互式的作业执行方式,支持Spark、PySpark、Spark R和Spark SQL类型的作业,分析结果可视化展示。
统一元数据
集群之间共享数据库、表的元信息,无需重复创建。
完全兼容Spark生态
100%兼容开源Spark,迁移成本低,性能表现优异。Databricks Runtime
在Apache Spark基础上做了大量的性能优化,且针对阿里云OSS做了I/O优化,提供了更快速、更高效的计算引擎。
Databricks Delta Lake
较开源Delta Lake,功能更完备,对核心功能点均有更深度的优化和性能提升。
企业安全性
与阿里云RAM集成,可以根据用户和角色做权限控制,保障数据安全性。实时计算Flink
阿里云基于 Apache Flink 构建的企业级、高性能实时大数据处理系统,由 Apache Flink 创始团队官方出品,拥有全球统一商业化品牌,完全兼容开源 Flink API,提供丰富的企业级增值功能。
了解更多大数据平台EMR
EMR是云原生开源大数据平台,向客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、ClickHouse、StarRocks、Delta、Hudi等开源大数据计算和存储引擎。EMR计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK平台。
了解更多机器学习平台PAI
面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。
了解更多